记忆,以及创造性思维
这是一个外行人的碎碎念,仅代表没有认真了解过NLP/推荐系统的非专业人士对未来的随机猜想
补充:以及没有学过强化学习
:本文更多的是臆想
我上大学第一节人工智能课的时候,我们的朱松纯院长就说啊,
符号落地和常识获取是笼罩在人工智能之上的两朵乌云。但似乎一切都变了,从 chatgpt 的出圈。
我们似乎找到了一种符号落地的方法。
Intro
- 在上一篇文章中提到,高维向量空间极有可能是一种合理的符号落地的方案。随着多模态技术的发展人们越来越重视向量空间。
- 在这一篇文章里,我会简要介绍增强检索,抛砖引玉地给出一种记忆的建模方式。
- 我最近一个礼拜总是试图思考如何将一些玄学的东西和AI结合起来,记忆的建模给了我一种方案,我相信这是一条能让大模型学会冥想的可能的尝试。
- 在记忆的基础上,我们能够阅读更长的文档,思考更多的内容,探索更大的世界。
- 譬如我们阅读完了一个领域所有的paper,并不断地反思不断地总结,会不会就成为了一个
idea自动生成器呢?既然 COT 被证明其行之有效,Very Long COT / GOT 从直觉上来说也是有效的。 - 但是 TOT 却又有一定的问题,任务导向形的思考能得到好的发散吗?在上一篇文章里我提到,向量相似度给了人们联想的理由,既然计算机拥有极大的算力,天马行空的联想能不能创造一些新的东西呢?
- 大数据,小任务是一回事,但是一旦我们拥有了一个可以用于联想的大脑,这个大脑是不是也能小数据,大任务一番呢?联想和泛化是人类创造力的来源。而这一切,却又基于一个合情合理的记忆建模。
前言
- 曾经有一段时间我看了好多奇怪的书,譬如教你如何集中注意力。
- 奇怪的书里说,我们的瞬时记忆就像一张白纸。我们用自动褪色的墨水笔在纸上写,写着写着就不见了过去。
- 最近一个知名的工作是StreamingLLM。
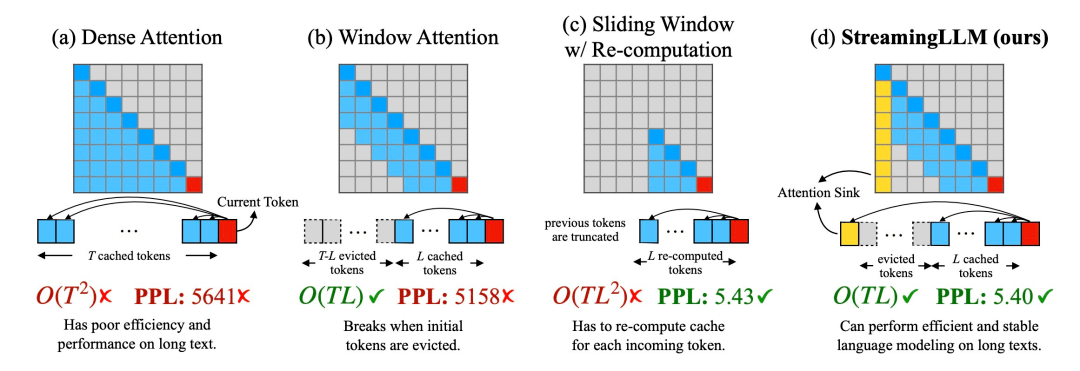
- 现在,LLM已经成了一个可以不断运行的用不终止的思考机器了,只不过上下文总是最新的。就像在用自动褪色的墨水笔在白纸上写字,写着写着,之前写的字也就被忘记了。
我们在我们的白纸上不断写下新的故事,譬如现在是
2023年10月17日,譬如坐在教室前面的小哥哥穿着黑衣服。那么——我们能留下什么,我们的记忆是什么。
Vector DataBase As Memory很多人说,向量数据库就是大语言模型的记忆。但至少,向量能代表很多东西。任何一个学习计算机的人都知道计算机的存储是
hierarchy的,从 Register 到 Cache 到 硬件。Blum夫妇用某一种视角,提出了
Conscious Turing Machine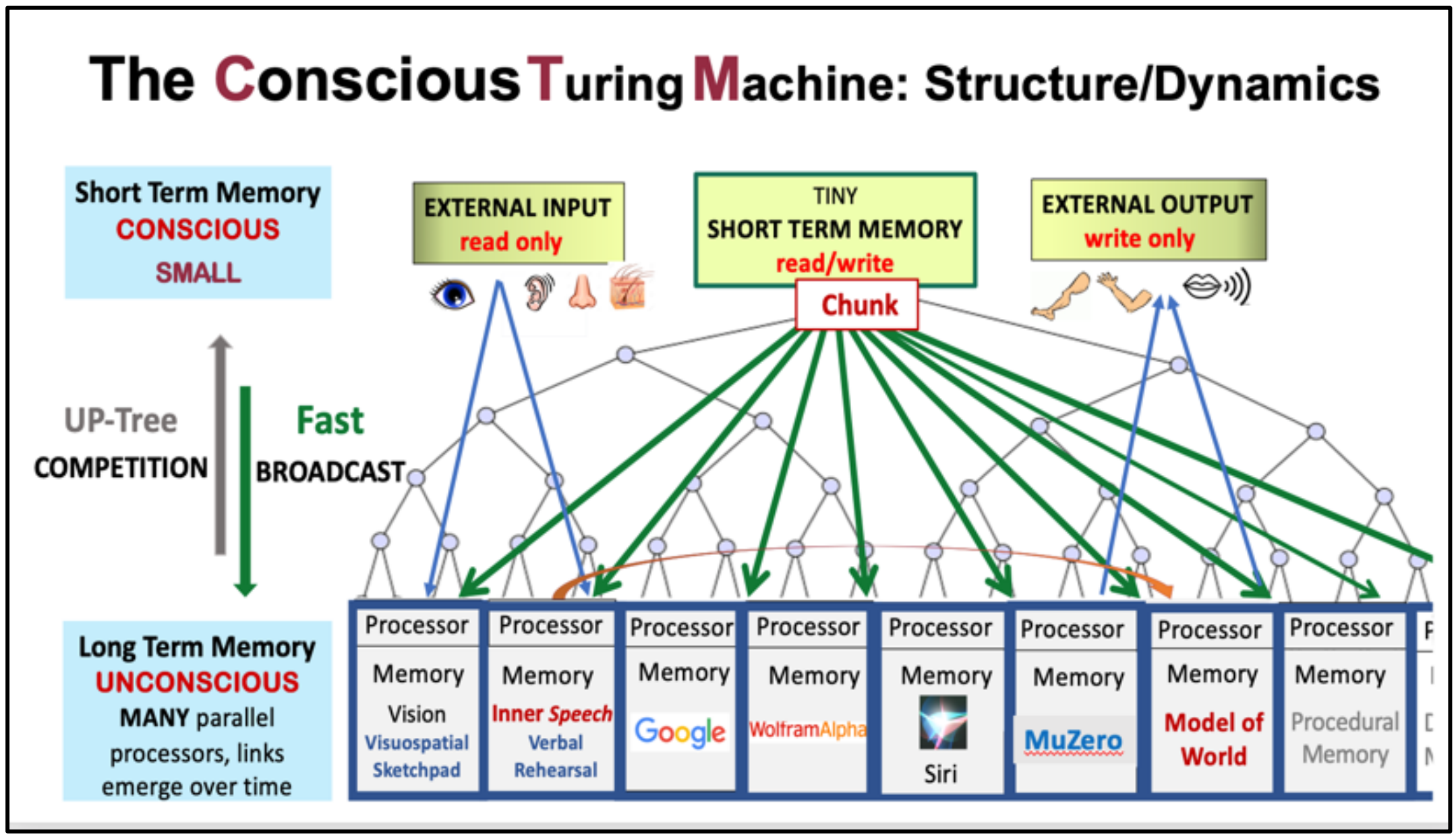
他把记忆分成了,长时记忆和短时记忆。长时记忆通过
UP-Tree上传。一个很自然的想法是,StreamingLLM所代表的Prompt上下文就是一种短时记忆,VectorDatabase就是一种长时记忆。
我们不会总是知道长时记忆,但我们总能从长时记忆中获取一定的信息。
Agent Memory
https://lilianweng.github.io/posts/2023-06-23-agent
in
A Survey on Large Language Model based Autonomous Agents短期记忆类似于转换器架构约束的上下文窗口内的输入信息,长期记忆类似于外部向量存储,代理可以根据需要快速查询和检索。
记忆方式
Unified Memory: 短期记忆,上下文实现
Hybrid Memory: 长期记忆和短期记忆相结合。
Reflexion utilizes a short-term sliding window to capture recent feedback and incorporates persistent long-term storage to retain condensed insights. This combination allows for the utilization of both detailed immediate experiences and high-level abstractions.
记忆存储
- Natural Languages: 使用原始自然语言直接描述诸如代理行为和观察的记忆信息。
- Embedding:基于嵌入的检索,
- Database: 直接利用SQL语句增加删除修改内存信息,
DB-GPT - Strutured Lists: 通过自定义结构化,比如子目标树
A notable example is the memory module of GITM [184], which utilizes a key-value list structure. In this structure, the keys are represented by embedding vectors, while the values consist of raw natural languages. The use of embedding vectors allows for efficient retrieval of memory records. By utilizing natural languages, the memory contents become highly comprehensive, enabling more informed agent actions.
记忆操作
应当实现:读取,写入,反思
reading: 需要利用的信息包括最近性,相关性,重要性。

writing: 主要考虑减少冗余存储,以及防止内存溢出。
reflexion: Generative Agent一文根据最近的记忆生成三个关键问题,然后查询记忆获得相关信息,产生五个见解,反思过程分层发生,根据低级见解生成高级见解。Expel中,Agent比较成功或失败的轨迹,然后从成功的案例中学习经验。
Agent planning
其它奇奇怪怪的东西
Retrieval meets Long Context Large Language Models一文里,作者提到利用检索增强的,具有4K上下文窗口的LLM,可以通过对长上下文任务进行位置插值来实现与具有16K上下文窗口的微调LLM相当的性能,证明了检索可以显着提高LLM的性能,无论其扩展上下文窗口大小如何。MemGPT: Towards LLMs as Operating Systems,作者提出智能管理不同内存层的系统,以管理会话和查看更多的上下文。Tree of Thoughts: Deliberate Problem Solving with Large Language Models,作者利用 Tree of Thoughts 的方法,结合记忆检索来扩展思考的范围,实现在数独等需要搜索的问题上超越GPT4的性能。Reflexion: Language Agents with Verbal Reinforcement Learning一文,作者利用自反省的方式,结合长时记忆,利用语言反馈在许多场景中获得了SOTA。MemoryBank: Enhancing Large Language Models with Long-Term Memory指出受到 Ebbinghaus Forgetting Curve theory 的启发,指出面向交互场景的陪伴形机器人,应当允许人工智能根据所经过的时间和记忆的相对重要性来遗忘和强化记忆。指出简化的模型,使用 $R=e^{-t/S}$ 其中 $t$ 为时间,$S$ 为回忆强度。Augmenting Language Models with Long-Term Memory
记忆与反思
- 在上一篇文章已经提到,在某种意义上我认为embedding是更好的存储方式,一个好的Agent应当满足以下的性质。
- 思与学应当有机结合。
- 1、应当以向量嵌入等高效的检索方式作为长期记忆。
- 一个Agent应当长时间,甚至是无限长时间运行,其学习过程和反思过程都应当被记录下来,也即整个过程是极为庞大的。尤其是记忆的内容还应当包括图片等。
- 2、应当能实现并发地反思,反思能增强记忆与理解。
- 一个Agent应当能自动整理记忆中的内容,并进行推理总结归纳演绎,以做到一定的创造。
- planning和reflexion应当能实现并行化,并行过程中能够同时利用和增强同一份记忆。以MCST为例,计算机应当充分利用其计算能力扩展其认知。
- 3、记忆应当与最近性,相关性,重要性相关。
- 在有限的上下文作为短时记忆的时候,必然需要将重要的内容和更相关的内容作为提取的记忆。
- 记忆应当对最近性建模,以防止过去陈旧的错误内容无法被修正
- 记忆应当对相关性建模,这个观察基于人类对某件事情的理解,细节越丰富也就越能回忆。
- 记忆应当对重要性建模。
- 记忆应当自适应地调整其记忆强度与权重,以实现记忆检索时上述三者的权衡。
- 4、Agent接受人类反馈与外部知识。
- 过去的工作中,Generative Agent实现了[3,4],Reflexion实现了[1,4],
Goal
- 基于上述假设,以下可以是Agent的目标。
- 1、长上下文,一句一句地阅读文本,阅读过程中进行反思,以1K上下文区间通过多次推理实现效果不弱于32K上下文区间。
- 2、在阅读完整个领域的paper后,能创造性地总结出领域特定Insight。
- 3、实现AGI。
一种可能的记忆建模
- 假设记忆存储在的向量空间为 $\mathcal V$ ,上一时刻时间为 $t$ ,当前时刻时间为 $t+1$
- 设函数 $F(t,I) : \mathcal V\times R \to R$ 代表记忆强度,$I$ 表示重要性,$G(o,\lambda) : \mathcal V\times R \to R$ 代表一个以 $o$ 为中心的高维高斯分布
- 对于记忆检索,以 $o$ 为embedding,所获取的记忆应当以概率 $G(o,\lambda) \cdot F(t)$ 得到。
- 对于时间衰减,则 $F(t+1,I) = F(t,I) \times e^{-\alpha /I}$
- 对于记忆写入,则 $F’(t,I) = F(t,i) + G(o,\lambda’)$
- 对于离散化的记忆,则以最近邻得到。