还是开一个新坑,说不定就学了呢。
HR:你连cs224n都不会你还敢投简历?
我:对不起我不敢
Stanford CS 224N | Natural Language Processing with Deep Learning
我不明白,我实在不明白,这是一门开了二十四年的课程,为什么他能一直与时俱进,而我能接触到的例如算法设计与分析等校内就不是这样。
很久以前看到neural turing machine的时候感觉,transformer就是自然而然地从中脱颖而出的。
但是还是不懂这些东西,可能有很多很多经典的原理,有一条脉络。
只是练一练英语,六级刚过的水平能不能听懂一些
前七课应该只需要快速过一下,虽然可能也很深刻。
前三次作业跳过
从作业4和作业5开始做
发现面向LLM学习真是一个好方法,这些经典的东西最好玩的就是你告诉LLM,让它帮你举一个例子,然后你就能看着这个例子就看懂了。
一些精简版
Lecture 1
todo.
Lecture 2
Distributed Representations of Words and Phrases and their Compositionality (Mikolov et al. 2013)
也就是又一些负样本,这里的 $\sigma$ 是sigmoid/logistic function。
Glove: 希望能Fast training,但是也能scale,在small copus上也能有用。
具体而言,希望能利用上这个称之为共出现矩阵的东西。
希望,$w_{i}^Tw_j=\log p(i\mid j)$,就是 $w_i^T(w_a-w_b)=\log \frac{P(i \mid a)}{P(i \mid b)}$
where X is the co-occurence matrix, and $f$ is to cut high value, like $f(x) = \min(x,C) / C,$ x > 0
(Why need f term? scale things on the frequency of the words, pay more attention to words that are more common)
evaluate word vectors:
- intrinsic word vector evaluation:
a:b :: c:?,man:woman :: king:?
and we have $d = \arg \max _i\frac{(x_b-x_a+x_c)^Tx_i}{||x_b-x_a+x_c||}$ ,
one trick is that let $d\not =a,b,c$.
- extrinsic: things like named entity recognition and etc.
Word Sense:
Improing Word Representations Via Global Context And Multiple Word Prototypes (Huang et al.2012)
things like pike has many meanings, so maybe we need to have different word vector?
Idea: Cluster word windows aroudn words, retrain with each word assigned to multiple different clusters.
感觉不如attention,果然transformer非常完美解决了这个问题,不愧是十二年前的NLP了。
Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, Ma, TACL 2018)
$v_{\text{pike}}=\alpha_1 v_1+\alpha_2v_2+\alpha_3v_3$
and let $\alpha_1 = \frac{f_1}{f_1+f_2+f_3}$… for frequency $f$, and actuallly, In applications,
This is enough!
可以理解为由于单词存在于高维的向量空间之中,不同的纬度所包含的含义是不同的,所以加权平均值并不会损害单词在不同含义所属的纬度上存储的信息
Lecture 3
这一节与NLP关系不大,大概是一些神经网络的基础知识× 读者需要对梯度下降,反向传播,Jacobians有一点了解
Named Entity Recognition(NER)
一个NLP的任务,
- find and classify names in text.
simple Idea: classify each word in its context window.
换言之就是给一句话,比如整个窗口五个词,中间这个词二分类一下看是不是一个类别。
这个任务的但难点在于,很难计算出实体的边界,
Lecture 4 - Dependency Parsing
Syntactic Structure:
有两种主要的观点,一种是Constituency grammar =phrase structure grammar,大概是上下文无关文法
- 基本概念:成分句法分析基于短语结构语法理论,该理论认为句子由一系列嵌套的短语组成,这些短语是句子的基本构建块。每个短语由一个中心词和可能的修饰词组成。
- 结构特点:在成分句法分析中,句子结构被表示为一个树状图,称为短语结构树或解析树。树中的每个节点代表一个短语或单词,节点之间的父子关系表示短语的嵌套关系。
另一种是 Dependency Parsing
- 基本概念:依存句法分析基于依存语法理论,该理论认为句子中的词通过依存关系相互连接。每个词(通常是名词、动词、形容词等实词)都有一个或多个依存词,形成一个依存关系树。
- 结构特点:在依存句法分析中,句子结构被表示为一个有向图,其中中心词(通常是动词或名词)是图的根节点,其他词作为子节点与之相连。每个依存关系都表示为一个有向边,边上标注了关系的类型(如主语、宾语、定语等)。

关于 San Jose cops kill man with knife
with prepositional phrase attachment ambiguites:介词短语附属不明确,但在中文不会出现×
Dependency Grammar and Treebanks
dependency: An arrow connects a head (governor, superior, regent) with a dependent (modifier, inferior, subordinate).
dependency grammar的历史悠久,可以追溯到5th century BCE,相比之下constituents/context free的历史是R.S. Wells 1947和Chomsky 1953这样过来的。
树库是包含大量句子及其结构化标注的语料库。这些标注可以是短语结构树(在短语结构语法中)或依赖关系树(在依赖语法中)。树库的目的是提供语言结构的实例,以便语言学家可以研究语言的规律,以及计算语言学家可以训练和测试自然语言处理系统。
例如,一个英语依赖树库可能包含成千上万个句子的依赖关系标注,每个句子都有一个如上所述的依赖结构图。这些标注可以用于训练句法分析器,该分析器能够自动识别新句子中的依赖关系。
已经标注的数据可参考 https://universaldependencies.org/
Transition-based dependency parsing
接下来我们考虑dependency parsing的方法
一种用于Dependency parsing的方法,此外还有的方法包括
- DP (Eisner 1996) , MSTPaser(McDonald et 2005)
- cs224n-2019-notes04-dependencyparsing.pdf (stanford.edu)
Greedy transition-based parsing
MaltParser [Nivre and Hall 2005]
让我们通过一个简单的例子来说明 MaltParser 是如何工作的。假设我们有一个英文句子:”The cat sleeps on the mat.” 我们将展示如何使用 MaltParser 的基于转移的依赖句法分析算法来构建这个句子的依赖树。
初始状态:分析开始时,我们有一个空的分析栈和一个包含所有单词的输入队列。
1
2栈: []
队列: [The, cat, sleeps, on, the, mat]应用 SHIFT 操作:我们将第一个单词 “The” 从队列移动到栈上。
1
2栈: [The]
队列: [cat, sleeps, on, the, mat]应用 SHIFT 操作:我们将下一个单词 “cat” 从队列移动到栈上。
1
2栈: [The, cat]
队列: [sleeps, on, the, mat]应用 RIGHT-ARC 操作:我们创建一个从 “cat” 到 “The” 的依赖关系,表示 “The” 是 “cat” 的定语,并将 “The” 从栈中移除。
1
2
3栈: [cat]
队列: [sleeps, on, the, mat]
依赖关系: cat --[det]→ The应用 SHIFT 操作:我们将下一个单词 “sleeps” 从队列移动到栈上。
1
2栈: [cat, sleeps]
队列: [on, the, mat]应用 RIGHT-ARC 操作:我们创建一个从 “sleeps” 到 “cat” 的依赖关系,表示 “cat” 是 “sleeps” 的主语,并将 “cat” 从栈中移除。
1
2
3栈: [sleeps]
队列: [on, the, mat]
依赖关系: sleeps --[nsubj]→ cat应用 SHIFT 操作:我们将下一个单词 “on” 从队列移动到栈上。
1
2栈: [sleeps, on]
队列: [the, mat]应用 SHIFT 操作:我们将下一个单词 “the” 从队列移动到栈上。
1
2栈: [sleeps, on, the]
队列: [mat]应用 SHIFT 操作:我们将下一个单词 “mat” 从队列移动到栈上。
1
2栈: [sleeps, on, the, mat]
队列: []应用 RIGHT-ARC 操作:我们创建一个从 “mat” 到 “the” 的依赖关系,表示 “the” 是 “mat” 的定语,并将 “the” 从栈中移除。
1
2
3栈: [sleeps, on, mat]
队列: []
依赖关系: mat --[det]→ the应用 RIGHT-ARC 操作:我们创建一个从 “on” 到 “mat” 的依赖关系,表示 “mat” 是 “on” 的宾语,并将 “on” 从栈中移除。
1
2
3栈: [sleeps, mat]
队列: []
依赖关系: on --[obl]→ mat应用 RIGHT-ARC 操作:我们创建一个从 “sleeps” 到 “on” 的依赖关系,表示 “on” 是 “sleeps” 的状语,并将 “sleeps” 从栈中移除。
1
2
3栈: [mat]
队列: []
依赖关系: sleeps --[advmod]→ on
最终,我们得到了句子的依赖树,其中 “sleeps” 是根节点,其他单词都是它的依赖项。这个过程是自动化的,MaltParser 使用机器学习训练的分类器来决定在每个步骤中应用哪个转移操作。分类器会考虑当前的分析状态和预定义的特征来做出决策。
投影性假设:MaltParser 最初是为处理投影性依赖结构(即依赖弧不交叉的结构)而设计的。这意味着它在处理非投影性依赖结构(即依赖弧可能交叉的结构)时可能会遇到困难。虽然后来有扩展来处理非投影性依赖,但这些扩展可能不如专门为非投影性语言设计的工具效果好。
该模型的精度略低于依赖解析的最高水平,但它提供了非常快的线性时间解析,性能非常好
啊,二十年前的东西
evaluation: (labeled) dependency accuracy
Lecture5 - Language Modeling
Neural Dependency Parsing:emnlp2014-depparser.pdf (stanford.edu)
- [Danqi Chen, Christopher D. Manning @ 2014]
解析算法(Parsing Algorithm):神经依存解析模型通常采用两种主要的解析算法:基于转移的系统(Transition-based Systems)和基于图的系统(Graph-based Systems)。
- 基于转移的系统:这类系统通过一系列的“转移”操作来构建依存树。模型根据当前的状态(包括已处理的单词和它们之间的关系)预测下一个转移操作(如SHIFT、LEFT-ARC、RIGHT-ARC等)。每个转移操作都会改变系统的状态,直到生成完整的依存树。
- 基于图的系统:这类系统将依存解析视为一个图上的优化问题。模型为句子中的每对可能的词对(head和dependent)分配一个分数,表示它们形成依存关系的概率。然后,使用图算法(如最大生成树算法)来找到最大化总分数的依存树。
a bit more about neural networks
Regularization:比如可以加一个
Frobenius范数 $w$,意思是可以增加一个超参数作为先验分布,使得权重较小以实现较好的泛化(?)Dropout:
dropout 本质上作的是一次以指数形式训练许多较小的网络,并对其预测进行平均。
最终的网络可以近似看作是集成了指数级个不同网络的组合模型。
Dropout一般是针对神经元进行随机丢弃,但是也可以扩展到对神经元之间的连接进行随机丢弃,或每一层进行随机丢弃。
在RNN中,不能直接对每个时刻的隐状态进行随机 丢弃,这样会损害循环网络在时间维度上记忆能力,一种简单的方法是对非时间维度的连接(即非循环连接)进行随机丢失。然而根据贝叶斯学习的解释,丢弃法是一种对参数θ的采样。每次采样的参数需要在每个时刻保持不变。因此,在对循环神经网络上使用丢弃法时,需要对参数矩阵的每个元素进行随机丢弃,并在所有时刻都使用相同的丢弃掩码。这种方法称为变分丢弃法(Variational Dropout)。 在与时间有关地地方,使用相同的丢弃掩码。
Normalization:其实也不知道LayerNorm还是BatchNorm,反正以后总得深刻地理解到底是哪一个,之后会搞懂的。
Mean Subtraction:大概就是一种数据处理。
Whitening:让所有特征具有相同的方差,
Parameter Initialization:在 Understanding the difficulty of training deep feedforward neural networks (2010) 的论文中,给出了一种随机分布,能让
sigmoid和tanh激活单元实现更快的收敛和得到更低的误差。Learning Rates:
更多的优化方法,An overview of gradient descent optimization algorithms (ruder.io)——这好像也已经是2016年了,好老啊。
n-gram
- using counting statistic approximation.
Language Model: to predict the next word.
Lecture6 - RNN&&more
Perplexity 困惑度是一种用于衡量语言模型好坏的方法
等价于 cross_entropy loss的exp版本。
gradient clip:gradient的范数超过某个阈值之后,clip掉。
LSTM:
- 为了解决梯度消失问题。
- 新的记忆只是被简单的加上去,在cell step上包括两步,forget门和input门。
- 前transformer时代的成功者
RNN的缺点:特别不稳定,因为repeated multiplication by the same weight matrix. [Bengio et al, 1994].
Lecture7 Seq2Seq, Attention
task: Machine Translation
- $\arg\max_y P(y\mid x)=\arg \max_y P(x \mid y) P(y)$
- 早期的Statistical Machine Translation
- 分成两份,左边就是一个Translation Model,右边用一个Language Model去预测 $y$ 发生的可能性。
关于翻译模型,往往加入一个叫做 Alignment 的东西,往往需要EM之类的算法去学一个
deepseek-chat:在统计机器翻译(Statistical Machine Translation, SMT)中,对齐(Alignment)是一个显式的过程,它需要明确地展示源语言和目标语言之间的对应关系。
它指的是源语言文本(source text)和目标语言文本(target text)之间的对应关系。这种对应关系可以是单词级别的,也可以是短语、句子甚至段落级别的。对齐的目的是为了帮助机器翻译系统理解源语言和目标语言之间的语义和结构上的对应关系,从而提高翻译的准确性和流畅性。
对齐就是一个分布迁移的过程
- 然后考虑如何做SMT的argmax这个方法,一个方法是引入强的独立性假设
关于SMT,怎么把这些部分结合起来,一种就是用动态规划的方法,比如说一个区间的词翻译成另一个语言,然后做一个 $dp[i,j]$ 那样的东西。应该很快,但是上个世纪了。
啊想起来了,最早读吴军的数学之美它讲统计机器翻译的。
seq-to-seq model
- 时间来到了2014年,祂出了,祂就是 Neural Machine Translation!
- 但chatgpt时代的我们应该知道seq-seq能做几乎所有任务。
- Multi-layer RNN 有好几层的RNN,有点像difussion相比于VAE的感觉。
含多个隐藏层,每个隐藏层都有自己的循环单元。每个时间步,信息不仅在同一层内的时间步之间传递,还在不同层之间传递。
- decoding: 用贪心或者用 Beam search decoding
- beam search decoding 类似于一个优先队列大小的启发式搜索。具体而言是 $\log p$ 的和。
- 缺点:可解释性,可控制性
BLEU score
BLEU(Bilingual Evaluation Understudy)是一种广泛使用的自动评估机器翻译质量的指标。它通过比较机器翻译输出与一组高质量的人工翻译参考文本来计算得分。BLEU 分数的范围通常是 0 到 1,其中 1 表示机器翻译与参考翻译完全匹配。BLEU 指标主要关注翻译的精确度,尤其是单词和短语的匹配程度,但它不直接评估翻译的流畅性或语义准确性。
- 精确度计算:对于每个n-gram,计算它在参考翻译中出现的次数。然后,计算机器翻译输出中匹配的n-gram的总数与机器翻译输出中所有n-gram的总数的比例。这个比例就是n-gram的精确度。
- 修正的n-gram精确度:为了避免过短的翻译输出得到高分,BLEU引入了修正机制。如果机器翻译输出中的某个n-gram出现次数超过了所有参考翻译中该n-gram的最大出现次数,那么这个n-gram的计数将被限制为最大出现次数。
- NMT:perhaps the biggest success story of NLP Deep Learning.
Assignment4
- cherokee-to-english translation
Attention
- RNN有一个 Information bottleneck,大概是encoder的最后一层。
- 原来这就是Information bottleneck!
- 一开始是
seq-to-seq with attention的模型,利用最后的bottleneck得到一个Attention scores,然后根据Attention Scores把注意力集中在RNN的每一层的输出。
Lecture8 Self-Attention&&Transformer
- bidirectional LSTM
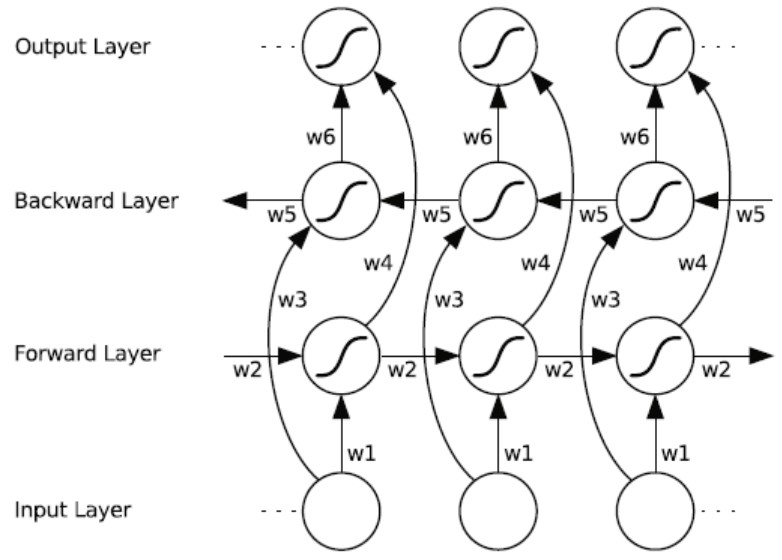
- RNN with Attention……
- 有很多之前的方法……大家想了很多很多方法
- RNN take O(seq length) steps for distant word pairs to interact.
为什么叫 self-attention?
之前一直用Neural Turing Machine的方法来理解成记忆的建模的
一句话,每个token都有一个注意力,关注这句话的各个部分。
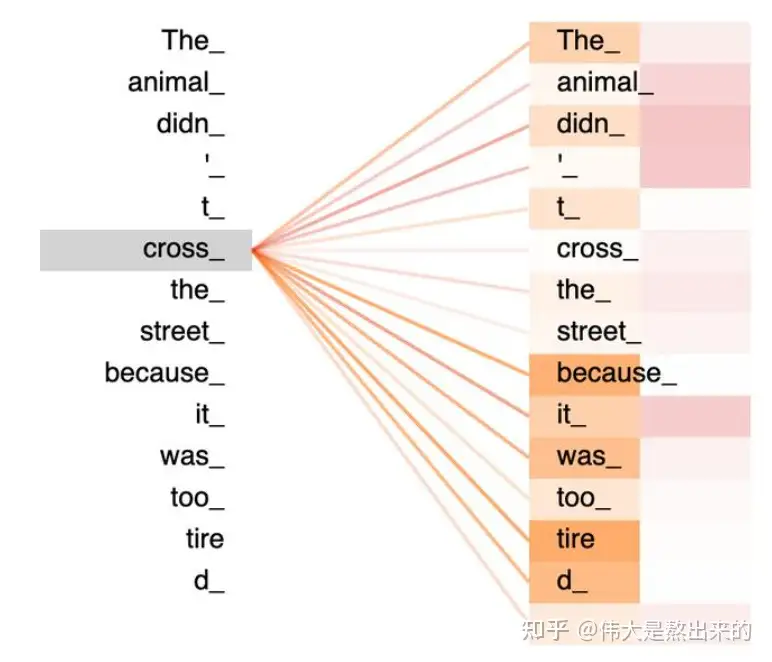
- order
- 然后一般再加上
sinusoidal position representations,不过unlearnable× - ok,那我们试试看学一个position embedding。然后让 $x’=x+p$,这里 $x$ 是一个每个词已经 embedding 之后的向量了。
- nonlinearities 在这之后,我们对于每个self-attention完了之后的部分可以用一个简单的FF网络作为非线性化层。
- don’t look at the future using mask our attention. — in decoder, we need to ensure we can’t peek at the future.
再放一张我很喜欢的解释KV-cache的图,只需要重新计算橙色的权重。
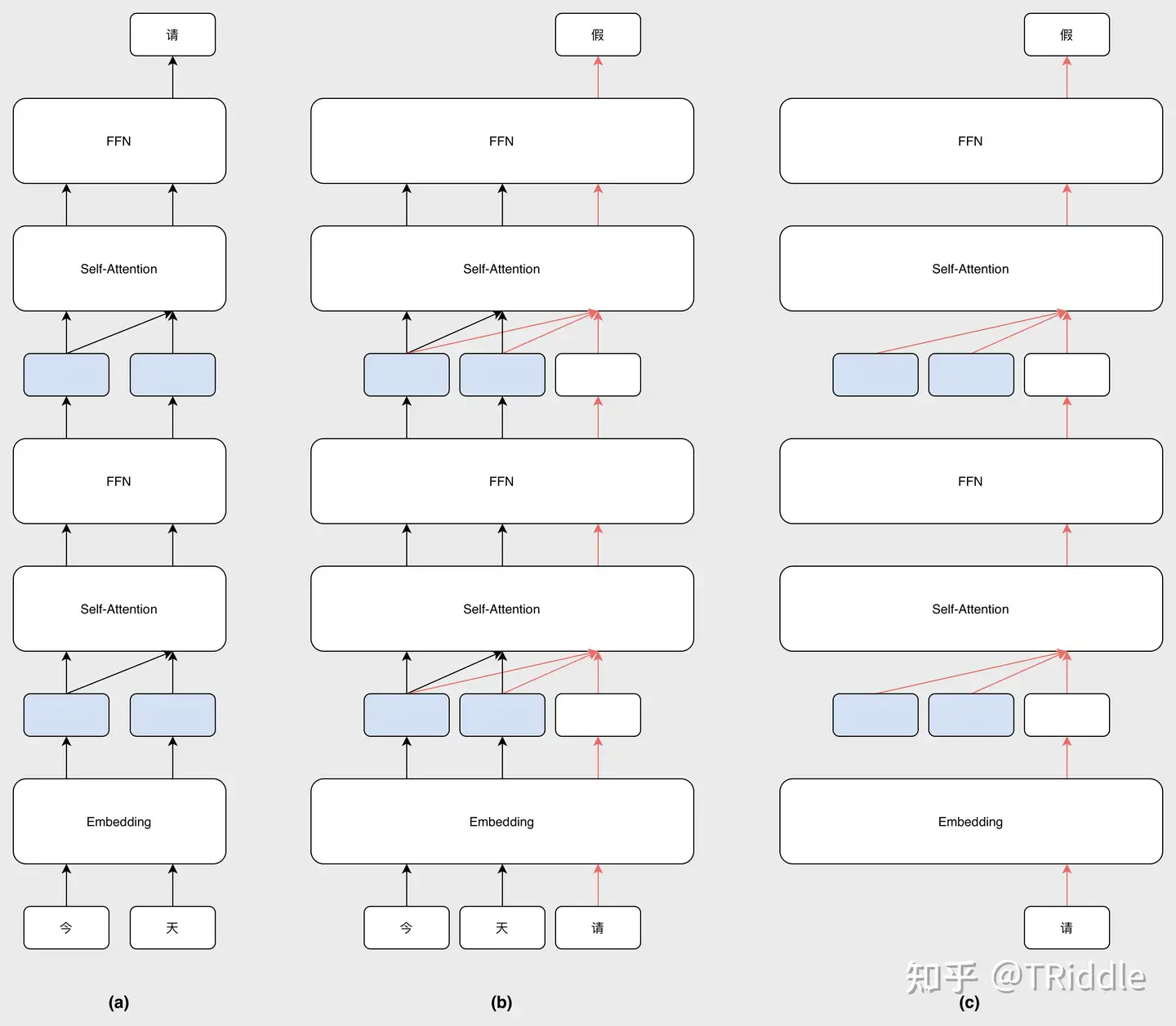
From Attention to Transformer
transformer is not necessary the endpoint of our search for better and better ways of representing language even though it’s now ubiquitous and has been for couple of years!
multi-head Attention
首先是用上了 multi-head Attention,就是可以用不同的注意力的方式注意不同的东西。
所有的self-attention可以用矩阵的方法,使得GPU-efficient
这里很重要,关于矩阵乘法形式的
不妨假设输入是 $d$ 维的,然后考虑原来的 $q_i,k_i$,也就是嵌入之后的向量,它们原来比如说也 $d$ 维的,然后我就把这个 $q$ 变成 $h$ 个,也就是变成了 h 个 $d/h$ 维的向量。
ok这样的话考虑已经固定了一个头Head,对于一对 $q{ti}$ 和很多 $k{tj}$,其中 $t \in [0,d/h)$,就得到了一个标量,经过softmax之后得到了一个长度为 $d$ 的概率分布,这个 $d$ 维的概率分布再和 $d$ 个 $d/h$ 维的向量 $v_i$ 做加权和,得到了一个 $d/h$ 的值。所以这里的 $Q_t,K_t,V_t$ 都是 $R^{d\times d/h}$ ,最后把 $h$ 个拼接起来就是一个 $d$ 维的,也就是完成了 $q_i$ 这个地方的query后的output。
矩阵计算的方法是这样的:
首先让 $XQ,XK,XV\in R^{n\times d}$,然后reshape成 $R ^{n\times h\times d/h}$,对于每一个维度计算 $softmax(R^{n\times d/h} \times R^{d/h \times n}) \times R^{n\times n/d}\to R^{n\times d/h}$ 对于tensor的每一个维度都是这样的,也就是得到了一个 $R^{n\times d/h \times h}$ 的张量,最后reshape成 $R^{n \times d}$ 的。
Scaled Dot Product
- 由于长度很长,为了让attention的softmax可以好用一点
- 还要除以一个 $\sqrt {d/h}$,这个是维度,一个结论是 $q$ 和 $k$ 是相互独立的,所以
- $Var(q_i)=E[q_i^2]-(E[q_i])^2=1=Var(k_i^2)$
- $Var(q_ik_i)=E[q_i^2]E[k_i^2]-(E[q_i]E[k_i])^2=Var(q_i)Var(k_i)=1$
- 所以 $Var(q^Tk)=d_k$,所以除了这个东西就能让方差都归一化,防止softmax都跑得很远然后导数很小不好优化。
Residual Connections
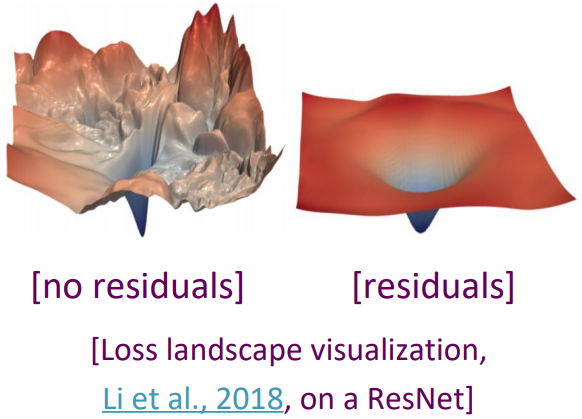
Layer Normalization
- a trick to help models train faster.
- 好用的原因可能是它的normalizing gradients:[Xu et al. 2019]
- 对于所有输入的 $x_i\in R^d$ 的词向量做,首先算出所有 $x_i$ 的均值,然后算出方差。
- 输出 $\frac{x-\mu}{\sqrt \sigma + \epsilon} * \gamma + \beta$。这里的 $\gamma \in R^d$ 和 $\beta \in R^d$ 可以省略。
- do not share across the batch.
Transformer decoder
于是我们就得到了:Transformer!
- embeddings -> position embeddings ->
- [—>Multi-head attention -> add(residual)&norm -> FF -> add&norm—>] * N
- -> Linear -> Softmax -> probabilities.
如果需要encoder+decoder,在decoder阶段就是
- Masked Multi-head Attention 之后作为query,然后把 encoder 过来得作为key和value。
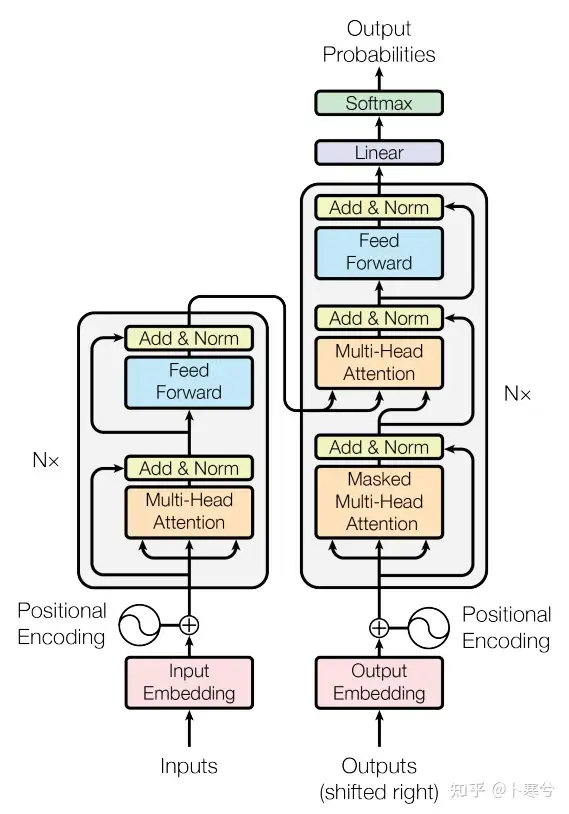
- 所以这里有一个cross attention
但是现在的Llama都是Decoder only的
据说有很多原因,包括Decoder only的注意力矩阵的秩很大?
- 然后就attention is all you need了,但是有两个问题
关于平方复杂度
- In practice, almost no large Transformer language models use any but the quadratic cost attention we’ve presented here. The cheaper methods thend not to work as well at scale.
- 2102.11972 (arxiv.org)
关于position embedding
- Some more flexible representations of position:
- Relative linear position attention (Shaw et al., 2018)
- Dependency syntax-based position (Wang et al., 2019)
Lecture9 - Pretraining
- 妈的,这个老师好帅啊,真的好帅啊
Word structure and subword models
有限的词表会让有些新的词好像没有出现过,那咋办呢
the byte-pair encoding algorithm
- 初始化:将输入文本分割成单个字符的序列,每个字符作为一个token。
- 统计频率:统计文本中所有字符对的出现频率。
- 合并:选择出现频率最高的字符对,将其合并成一个新的token。这个过程会重复进行,每次都选择频率最高的字符对进行合并,直到达到预定的token数量或满足其他停止条件。
- 编码:使用新生成的token集合对文本进行编码。
hat->hat learn->learn taaaaasty->taa## aaa## sty laern->la## ern## Transformerify-> Transformer## ify
为什么分成了pretrain和finetuning
- 高质量数据不多的问题?
encoder
- encoder的pretrain的方法,给一个句子(mostly randomly)mask掉一部分,比如
I __ to the __,然后去预测went,store。 - bert
- 有时候用一个随机的词替代,有时候用mask,有时候原样输出。
- 除了token embedding,position embedding,还有一个segment embedding。[后来的工作说next sentence prediction是不必要的]
- 只有110M和340M的大小。
- finetuning方法可以是:prefix-tunning, prompt tuning.
- 也可以是:对于所有的网络W(n m),弄一个低秩的A(n d)和B(d * m),然后 W+AB
encoder-decoder
- 训练的方法类似bert的方法
- T5
- 非常fantastic的事情是,人们发现finetuning的时候,模型有很少的时候能从pretrain里获取一些在finetuning过程中没有见到的内容和信息。
- it learned this sort of implicit retrival sometimes.
decoder
- predict the next word
- 在课程中没有提及为什么大部分大模型都是decoder only的架构,老师表示可能是参数少能一起用。
- GPT
- 发现了 In-context learning,但很神奇我们不知道为什么会有in-context learning。
那么应该用多少的token训多大的模型呢:scaling Efficiency
- Chinchilla!70B parameters and 1.4Trillion tokens.
The prefix as task specification and scratch pad: chain-of-thought.
- 依然不知道为什么能work
pretraining学了些什么?
trivia, syntax, coreference, lexical sematics, topic, sentiment, some reasoning, some basic arithmetic, …..
所以这个意义上搞数学是不是还是很合理的。
Lecture10 - from LM to Assistants.
有至少三种方法来align AI和人类
- Zero-shot/Few-shot
- Instruction finetuning
- Reinforcement learning from human feedback [still data expensive]
- what’s next?
- Zero-shot learning
- Speicifying the right sequence prediction problem
- comparing probabilities of sequences.
- Zero-shot chain-of-thought prompting.
- few-shot learning
Instruction finetuning
- 在一些task上做finetuning可以泛化到其它的任务。
于是出现了 MMLU 在不同的benchmark上的测试。
除了太贵了,两个问题
- Tasks like open-ended creative generation have no right answer.
- language modeling penalizes all token-level mistakes equally, but some errors are worse than others.
基于上面这些问题,Instruction finetuning可能还不够好,所以出现了
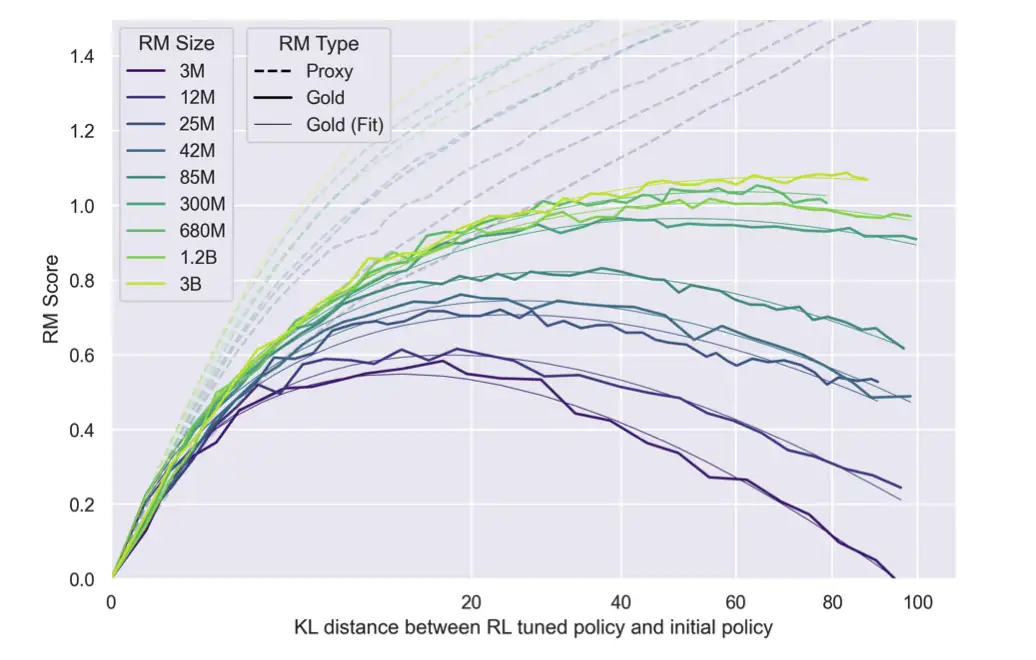
RLHF
带 KL 约束的带reward model的,其实我觉得入门RLHF应该用那篇Remax。
Can we directly using RLHF with the pretrained model?
30k tasks for SFT + RLHF
随着KL divergence增大,RM model的预测会和真实的preference偏离。 [Stinnnon et al., 2020]
so what’s next?
- RL from AI feedback?
- Constitutional AI? [2212.08073] Constitutional AI: Harmlessness from AI Feedback (arxiv.org)
- [2210.11610] Large Language Models Can Self-Improve (arxiv.org)
Lecture 11 - Natural Language Generation
关于open-endedness程度,可以评价一个生成任务的open程度【好像只是一个随便的介绍】
- Machine Translation不怎么open
- Summarization更open一点
- Task-driven Dialog更open一点
- chitchat dialog更open一点
- story generation更open一点。
For non-open-ended tasks, we typically use a encoder-decoder system. while for open-ended tasks, this autoregressive generation model is often the only component.
negative loglikelihood ,实验发现,随着你重复的越多它越容易觉得应该重复输出。即使是openai也容易不断地重复输出一部分。
这个好常见啊,就是不断地重复重复重复,然后mean长度起飞。
- unlikelihood objective(Welleck et al., 2020) penalize generation of already-seen tokens
- conveage loss(See et al., 2017) Prevents attention mechanism from attending to the same words.
此外,人类的输出往往不是概率最高的beam search的,所望sample往往是更好的?
Nucleus Sampling与不同解码策略简介 - 知乎 (zhihu.com)
decoding: top-k sampling
- language is a heavy tailed distributions.
- while k could be varies depending on the uniformity of $P_t$
- -> Top-p(nucleus) sampling
- 但其实这个 $k$ 其实和分布关系很大,所以一种方法是用entropy算k
- 没有减少compute,但是增加了performance,可以based on entropy.
scaling randomness: temperature
显然 $\tau$ 越小,越像argmax。
Re-ranking
- decode 10 candidates.(but it’s up to you)
define a score to approxiamte quality of sequences and re-rank by this score.
- perplexity? no [repetitive utterances generally get low perplexity]
- usually variety of properties:
- style, discourse, entailment/factuality, logical consistency, and many more…
- Beware poorly-calibrated re-ranker.
- can compose multiple re-rankers together.
我还发现了一点,中国人的英语发音真容易听懂。
Exposure Bias
Exposure bias causes text generation models to lose coherence easily.
曝光误差(exposure bias)简单来讲是因为文本生成在训练和推断时的不一致造成的。不一致体现在推断和训练时使用的输入不同,在训练时每一个词输入都来自真实样本(GroudTruth),但是在推断时当前输入用的却是上一个词的输出。
scheduled sampling (Bengio et al., 2015)
- 1.使用scheduled-sampling,简单的做法就是在训练阶段使用的输入以p的概率选择真实样本,以1-p的概率选择上一个词的输出。而这个概率p是随着训练次数的增加衰减。
- but lead to strange training objectives.
data aggregation
At various intervals during training, generate sequences from your current model
Add these sequences to your training set as additional examples
这个没搞懂,这个和exposure bias有什么关系?是不是
Retrieval Augmentation(Guu, Hashimoto,et al., 2018)
Learn to retrieve a sequence from an existing corpus of human-written prototypes(e.g., dialogue responses)
Learn to edit the retrieved sequence by adding, removing, and modifying tokens inthe prototype-this will still result in a more “human-like” generation
这个没搞懂,这个和exposure bias有什么关系?好像是为了让模型的输出更像人?毕竟是2018年的文章了,那时候还没有大模型
Reinforcement Learning: cast your text generation model as a Markov decision process.
how do we define a reward function? some evalutaion
- BLEU (Bilingual Evaluation Understudy)
- 用于机器翻译任务的评价指标。BLEU通过比较机器翻译结果与一组高质量参考翻译之间的n-gram重叠来计算得分。得分范围通常是0到1,其中1表示完全匹配。
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- CIDEr (Consensus-Based Image Description Evaluation)
- SPIDEr (SPan-based Image DEscriptors)
但是这些reward不一定就是human想要的。
- Cross-modality consistency in image captioning (Ren et al., CVPR 2017)
- 在图像字幕生成任务中,跨模态一致性指的是生成的文本描述与图像内容之间的一致性。例如,如果图像中有一只狗,那么生成的描述应该包含“狗”这个词。研究者们可能会设计一种奖励机制,以鼓励模型生成与图像内容高度一致的描述。
- Sentence simplicity (Zhang and Lapata, EMNLP 2017)
- Temporal Consistency (Bosselut et al., NAACL 2018)
- Utterance Politeness (Tan et al., TACL 2018)
- Formality (Gong et al., NAACL 2019)
所以不如 ! learned representations of words and sentences to compute sematic similarity. 比如BERTSCORE。
and Human Preference(RLHF) like reward model.
- 下游任务一般都需要 50K-100K 的数据
感觉RLHF的pipeline好像更合理一点?
Evaluating Open-ended Text Generation by MAUVE score.(2022,)
真实文本和生成文本之间的KL散度,$KL(P||Q),KL(Q||P)$
但是直接KL不行因为有零点,作者用了一个很巧妙的方法,他把两个概率分布以一定比例混合起来,这样就是一定能算KL。随着混合比例能得到一条曲线,曲线下方的就是。
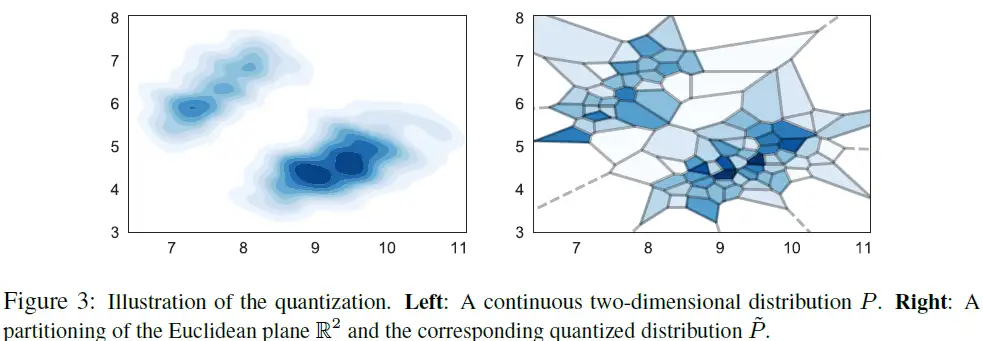
use k-means to transform a continuous text space to discreate type. and compute the forward/backward KL.
how to evaluate a metric
和人类打分的正相关性。
Note: Don’t compare humanevaluation scores acrossdifferently conducted studies
- Even if they claim to evaluatethe same dimensions!
- because human evaluations tends to not be well-calibrated. (expensive)
Lecture14 - Insights between NLP and linguistics
- 是不是有点像CV和图形学的关系?
Lecture15 - Code Generation
- todo
Lecture 17 - Model Analysis and Explanation
- 会不会有点过时了×
- 不如补一补今年旁听的那门可信机器学习。