本课又名林教授的人生哲理和他十五年前的工作,本笔记不包含人生哲理部分。
依然是学不会也没花太多时间学的一门课,靠,就是这种什么都不会,慌的一批的感觉。
学疯了,第五章第六章第七章第八章真的完全学不会。
草我不会是个傻子吧,怎么什么都不会啊。
我不会真是个傻子吧
Chapter1: Overview
这一节不是很重要
一定要写优化的变量,就是针对什么来优化的。
例如,SVM的优化是
GAN的优化目标是
Adversarial Learning的目标是
噪声要小,效果要好
Hyper parameter Search
Machine Learning = Representation + Optimization + Evaluation — Pedro Domingos
P. Domingos. A few useful things to know about machine learning. Communications of the ACM, 55(10):78-87, 2012
Is optimization difficult?
NO! [转载]来自南京大学数学系张高飞老师谢纳新新浪博客 (sina.com.cn)
代数几何>复分析、调和分析、微分方程>几何>动力系统>组合数学>统计>计算数学
最后这一条是专门针对那些悲情人物的。他们连小学的数学也没学好。不要说 把上千个数加起来,就是把两个数加起来,对他们来说都是件很吃力的事。然 而这一切丝毫没有削弱他们对数学的一片痴情。他们日日夜夜泡在图书馆里。 他们翻阅了所有的数学文献,却从未找到一本能读懂的。 但他们仍坚持不懈, 为的就是找到一个适合自己的专业。他们的行为感动了上帝。上世纪的某一天, 上帝为他们创造了一台机器帮他们计算。这就是计算机。借助计算机,他们可 以很快地进行加减乘除的运算。这就是计算数学。
No-free-lunch Theorem for Opt.
If algorithm A performs better than algorithm B for some optimization functions, then B will outperform A for other functions.
D. H. Wolpert and W. G. Macready, No free lunch theorems for optimization, IEEE T. Evolutionary Computation, 1, 67-82 (1997).
优化问题的分类
the nature of the solution set
- Continuous opt. problems
- Discrete opt. problems
- Combinatorial opt. problems
- Variational opt. problems
the description (definition) of the solution set
- Unconstrained, Constrained(Equality constrained,Inequality constrained)
the properties of the objective function
- Convex vs. nonconvex
- convex programs:
- quadratic program,semi-definite programs,second-order cone programs
- in ML, a lot of regression.
- nonconvex:要么是函数非凸,要么是约束域非凸。
- 比如分数规划,minmax问题,spare models
Chapter2 - math
Open set:开集
Closed set:闭集(补集是开集)
bounded set:有界集,每个元素的范数不超过一个 $R$
compact set:紧集,有界闭
interior:内点集,$C^o={y\mid \exists \epsilon>0,B_\epsilon(y)\sub C}$
closure:闭包集,补集的内点 $\bar C$
boundary:边界,$\bar C \backslash C^o$
Global Convergence: 每个点都能收敛到FONC ($\nabla f(x^*)=0$) 条件的点。
Local Convergence: 只有足够近才能收敛,否则不收敛(比如牛顿法)或者不FONC(比如鞍点)
Convergence rate:
$x_k \to x^*$
如果说 rate 为 $r$ ,rate constant为 $C$,说明
显然是 r 越大越好, C 越小越好。
线性收敛则 $r=1,0<C<1$,Q-linear
sublinear则 $r=1,C=1$, superlinear 则 $r=1,C=0$, Quadratic 则 $r=2$。r 可以不是整数。
比如 $xk=0.99^k,x^*=0,e{k+1}/e_k=0.99$ 这个就是线性收敛。
- 注意到 $\log ||e_{k+1}||\approx r \log ||e_k|| + \log C$,所以可以估计 $r$。
有时候不太能用 Q-linear收敛
- 如果 $||x_k-x^|| \le e_k$ 且 $e_k$ 以 Q-linear 收敛到零,那么 ${x_k}$ 就以 *R-linear 收敛,
closedness(函数的)
- 函数 $f$ 是闭的,如果对于所有 $\alpha$ 有 $\set{x \in dom f\mid f(x) \le \alpha}$ 是闭的。
也就是 $\text{epi} f={(x,t) \in R^{n+1} \mid x \in dom f,f(x) \le t}$ 是闭的。
连续函数只要定义域是闭的就是闭的,如果定义域是开的,那么到从内点到边界点的一个收敛序列的函数值必须是趋向于无穷。
$f(x)=\cases{x\log x& x>0\0&x=0}$ 是闭的, $f(x)=-\log x ,x>0$ 是闭的。$f(x)=x\log x,x>0$ 是开的
Derivative(函数的)
- 对于函数 $f:R^n \to R^m$
- 定义m*n 的 Jacobian矩阵 $J$ 的第 i 列为 $\frac{\partial f(x)}{\partial x_i}$。
Gradient
let $Z$ be close to $X$, $\Delta X=Z-X$ , $\lambda_i$ be the ith eigenvalue of $X^{-1/2}\Delta X X^{-1/2}$
Chain rule
when f is a real-valued
lets have a try at
Second derivative
H means Hessian.
so lets have a try of $f(x)=\log \det X$
Chain rules for second derivative
for $g(x)=f(Ax+b)$
Reparameterization trick
SVD
with $A \in R^{mn},rank A=r$, satisfies $U\in R^{mr},U^TU = I,V \in R^{n*r},V^TV=I$
for $\sigma_1 \ge \sigma_2 \ge …\ge \sigma_r >0$
norm
nuclear norm
usually used for approximating the rank of a matrix.
(p,q)-norm usually used in sparse representation.
dual norm
性质有
以及知名的Cauchy-Schwartz inequality
condition number
描述了矩阵对向量的拉伸和压缩能力。
对于 $Ax=b$,条件数唯一决定了线性方程的解关于观测的噪声的影响程度。条件数越大越严重。(x的变化率偏离b的变化率就更大)
Adjoint operator
von Neumann trace theorem
Suppose $A,B \in R^{m*n}$,then
convex set
- every two points can see each other.
$\empty, {x_0},R^n$
convex hull
- all the convex combination of points
- the smallest convex set contains C
这个习题必须重新做一遍,补一下回放吧
Cones
- $x\in C,\theta>0 \implies \theta x\in C$
convex cone
- $x_1,x_2\in C,\theta_1,\theta_2 >0,\theta_1x_1+\theta_2x_2 \in C$
conic hull
- conic combination of points.
affine set
- contains all lines passing through any two points. if x0 in C, C-x0 is a subspace.
dual cone
is closed and convex.
$K_1\subseteq K_2 \implies K_2^\subseteq K_1^$
$K^{**}$ is the closure of the convex hull of $K$.
subspace, non-negtive orthant, postive semi-definite cone, norm cone.
Operations that preserve convexity
Intersection,如 $S+^n=\bigcap{z\not=0}{X\in S^n\mid z^TXz\ge 0}$
Affine functions
- Sum and Cartesian product
- Perspective functions
- $P(\mathrm z,t)=\mathrm z/t$
- Linear-fractional functions
Separating hyperplane theorem
- 如果两个凸集是不交的,那么就存在一个向量 $a\not=0,b$ ,使得 $a^Tx-b$ 再一个集合大于等于零,一个集合小于等于零。
- 如果是严格不等,叫做Strictly separation
- 如果两个凸集至少有一个是开集,那么只要存在分割平面他们就不交。
考虑强二择一定理,即Faka’s Lemma
第一个如果有 $Ax=b,A^Ty\ge 0\implies b^Ty=x^TA^Ty\ge 0$
第二个如果 $Ax\not =b$,也就是 $b$ 在 $cone(A)$ 这个集合的外面,那么存在一个 $y$,使得 $\left
Supporting hyperplanes
- 非空凸集的任何一个边界上的点,至少存在一个支撑超平面。
- 也就是一个向外的方向 $a$,对于边界上的点 $x_0$,使得 $a^Tx \le a^Tx_0$。
Convex function
- 定义线性组合的函数值小于函数值的线性组合。
Rademacher’s Theorem 凸函数的几乎所有相对内点都可微。
Extended-value extensions
- 对于凸函数,把对于非定义域的地方扩充为 $\infty$,值域变成了 $R\cup{\infty}$
First-order conditions
如果函数可微,那么这个条件和函数凸等价
对于所有的 $x,y \in dom f$ 成立。
可以写成
Strongly Convex: $f(y)\ge f(x)+\left<\nabla f(x),y-x\right>+\frac{\mu}{2}||y-x||^2$
Second-order conditions: $\nabla^2 f(x) \succeq 0$
- Strongly convex: $\nabla^2 f(x) \succeq \mu I$,
- but for strictly convex, $\nabla^2f(x) \succeq 0$ ,and $\succ 0$ not holds.
sublevel
quasi-convex
- $f(\alpha x+(1-\alpha)y)\le \max [f(x),f(y)],\alpha \in [0,1]$
epigraph
proper function
- $f(x)<\infty$ for at least one x, and $f(x)>-\infty$ for all $x \in \mathcal X$ .
Jesen’s inequality
- $f(\mathbb E x)\le \mathbb E f(x)$
Bregman distrance
- $B_f(y,x)=f(y)-f(x)-\left<\nabla f(x),x\right>$
subgradient
- $\partial f(x)={g \mid f(y) \ge f(x)+\left
- 可以加法分解
- 可以链式法则,这里如果 $F=h(f(x))$在 $h$ 是convex 以及单调非递减的时候可以链式法则分解。
Danskin’s Theorem
- TBD
subdifferential of norms
证明分两步,一定要满足条件是容易的,还有一种是满足条件的一定是subgradint
用定义,$\left
函数保凸运算
- Nonnegative weighted sums
- Composition with an affine mapping,$g(x)=f(Ax+b)$
Pointwise maximum and supremum,
Composition – Scalar composition
- $f(x)=h(g(x))$
- 有两种情况
- h是convex而且非递减的,那么g是convex的
- h是convex且非递增的,那么g是concave的。
- 从 $f’’(x)=h’’(g(x))g’(x)^2+h’(g(x))g’’(x)$ 可以想到
比如 $-\log (-g(x)),\exp g(x)$ 在 $g(x)$ convex的时候
Composition – Vector composition
- $h(g(x))=h(g_1(x)…g_k(x))$
- 条件和上面一样的,不过对每个g都成立。
Minimization
epi g是epi f的一个投影!
Perspective of a function
- $g(x,t)=tf(x/t)$。
- epi g 是 epi f 的inverse mapping
- 比如取 $f(x)=-\log x$,就能得到相对熵是凸的。
conjugate function
(强烈建议看那张图)
examples
- affine function
- negative logarithm
- exponential
- negative entropy: $f(x)=x\log x,[xy-x\log x]f^*(y)=e^{y-1}$
- inverse
Fenchel’s inequality
such like take $f(x)=\frac{1}{2}||x||^2$ or $f(x)=\frac{1}{2}x^TQx$
conjugate of the conjugate
- If $f$ is proper, convex and closed, then $f^{**}=f$
- Suppose $\exists (x_0^T,\gamma)^T \not \in epi f$ , where $\gamma \ge f^{**}(x_0)$. Since $f$ is proper, convex, closed, its epigraph is closed and does not include a vertical line. Thus since t can very large, let $\zeta$ must be negative. assume $\zeta = -1$, take $t=f(x)$Thus $f^(w)<w^Tx_0-f^{*}(x)$
contradicting Fenchel’s inequality
For any $f$, $f^{**}$ is the largest convex function not exceeding f.
if $f(u,v)=f_1(u)+f_2(v)$, then $f^(w,z)=f_1^(w)+f_2^*(z)$
Envelope function and Proximal mapping
- $Env_c f(x)=\inf_w{f(w)+\frac{1}{2c}||w-x||^2}$
- $Prox_c f(x)=\arg\min_w{f(w)+\frac{1}{2c}||w-x||^2}$
proximal gradient
where $g$ is L-smooth, $f$ non-differentiable but having easily computing proximal mapping
if $f(u,v)=f_1(u)+f_2(v)$, both closed proper functions.
能证明
也就是
Moreau Decomposition
proximal mapping
if f is convex, the proximal operator is 1-Lipschitz and the envelope function is (1/c)-smooth.
proximal mapping of a norm
where B is the unit ball of the dual norm $||\cdot ||_*$
Unconstrained Optimization
Descent methods
停止准则是 $||\nabla f(x)||_2\le \eta$
Exact line search: 去求min
Backtracking line search: while $f(x+t\Delta x)>f(x)+\alpha t \nabla f(x)^T\Delta x$, do $t=\beta t$
gradient descent method: $\Delta x=-\nabla f(x)$
如果强凸则有
在这种情况下,一旦 $\nabla f(x)$ 足够小,我们就有对于任何一个 $y$,取 $\tilde y=x-(1/m)\nabla f(x)$
上面的结论是
另外我们还有一个upperbound,然后有一个 descent lemma
如果M-smooth,最大特征值被bound
那么
也就有
也就有对于新的 $x^+$,对于exact line search
linear convergence.
对于backtracking line search,要分情况讨论,关于有没有发生,这里看不懂跳过。
steepest descent method
- 对于二模的最速方向确实就是 $-\nabla f(x)$,但是对于矩阵 $P$ 下的模是,$-P^{-1}\nabla f(x)$,需要归一化一下。
对于L1的则是:
算出来是最大的方向的负。
newton’s method
Theorem 2: Newton’s Method for Strongly Convex Functions
Theorem: Suppose that $f \in C^2$ is strongly convex, with Lipschitz continuous second order derivative:
and $x^ \in \mathbb{R}^n$ is a local minimizer. Then, for all $x^{(0)}$ sufficiently close to $x^$, Newton’s method converges to $x^*$ with order of convergence at least 2.
Proof:
Let $x^{(k)}$ be the $k$th iterate of Newton’s method, defined by
Then, we can write
Using the strong convexity of $f$, we have
Expanding the first term on the right-hand side, we get
Substituting this into the inequality above, we get
Completing the square on the right-hand side, we get
Since $m > 0$ and $L > 0$, we can choose $\delta > 0$ such that $m - \frac{L}{m} \ge \delta$ for all $x^{(k)}$ sufficiently close to $x^*$. Then, we have
This shows that Newton’s method converges to $x^*$ with quadratic rate of convergence.
conjugate gradient algorithm
目的是包括
此外所有的 $Q^{1/2} d^{(i)}$ 也是两两正交的,也就是要 $d^{(i)}Qd^{(j)}=0$
Quasi-Newton Methods
- 估计hess矩阵
Rank One Correction Formula
要让
展开解这个 $z^{(k)}$
- 但是rank one的修正有问题,不保证positive definition
DFP algorithm
- 也是一个公式,但真消化不了这么多了。
- 先pass吧,考了也没办法。
BFGS algorithm
- 维护一个矩阵 $B$,$B$ 是用DFP的方法来更新的。
- 然后用 $B_{k+1}^{-1}$ 来估计 BFGS的H,然后求逆可以直接展开。
L-BFGS
- 只用几个变量来估计 $B$
Majorization Minimization
- 就那个MM算法,看之前的博客吧,但也学不会。
optimality conditions
local first order condition
KKT condition
KKT-point $(x,\lambda,\mu)$
SCQ condition
The functions $g_i$ are convex for all $i\in \mathcal I$
where $\mathcal I_{1}$ is the index set of nonlinear constraints.
=>ACQ $c_l(x_0)=c_t(x_0)$ =>GCQ: $C_l(x_0)^=C_t(x_0)^$.
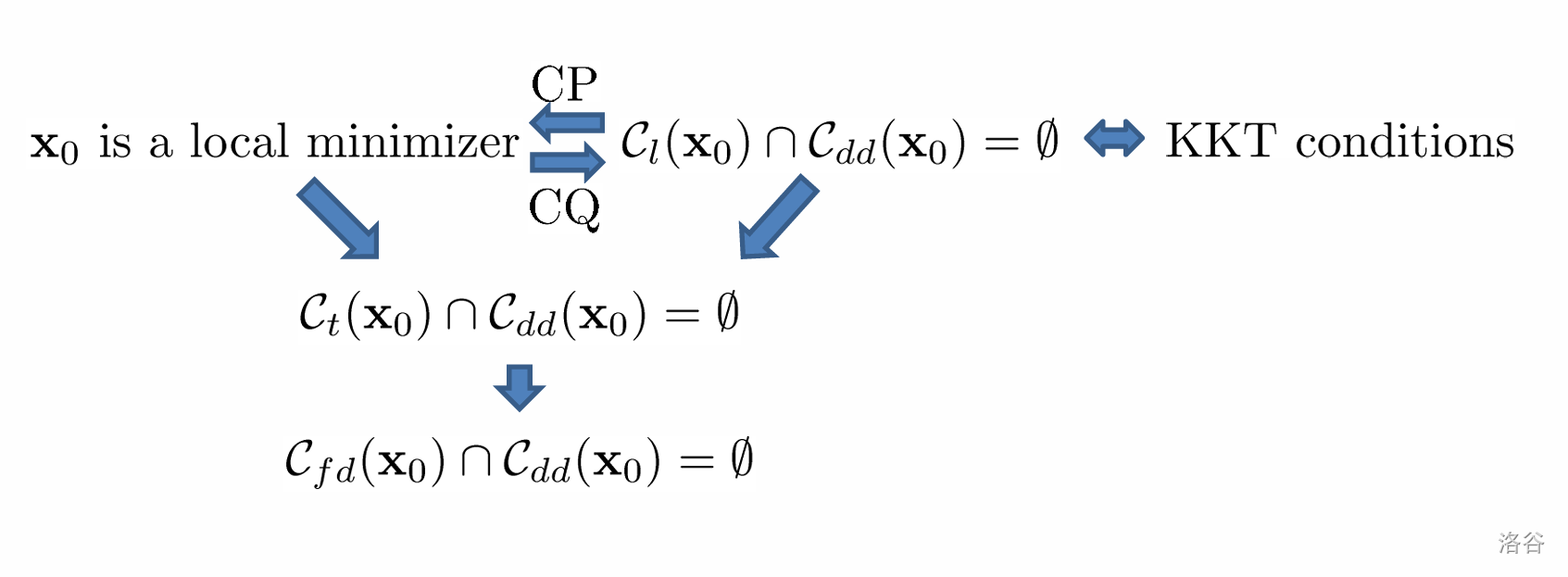
duality
- 如果SCQ就是strong duality的。
不是我真学不会啊啊啊啊
Unconstrained Optimization
projected gradient descent
dual method
Newton’s method with equality constraints
penalty method
frank-wolfe algorithm
- 直接在定义域内做线性化,找到线性化之后定义域内最优的那个点,$s_k$,让$s_k-x_k$作为下降方向。
Lagrangian method of multiplier
augmented Lagrangians and the method of multiplier
Alternating Direction Method
$\min_{x,y} f(x)+g(y),s.t. A(x)+B(y)=c$, where f and g are convex, A and B are linear mappings.
the augmented Lagrangian function:
then
- $\beta$ can be $\tau \beta$, $\tau\in(0,(1+\sqrt 5)/2)$
- 我们假定那个argmin是容易的,才容易把这个做下去。
example: RPCA(robost PCA)
LADM
- 把二次项做线性化,
这里面最有意思的是,两种闭解的形式。
一种是一范数的proximal的close form,类似于
一种是二范数的proximal的close form,类似于
辅助变量等价变形
- 原来的问题如何做一个re-fomulation让它更好解。
- 如果一个东西是有close-form solution的话就比较好解。
LADMAP
Lin et al., Linearized Alternating Direction Method with Adaptive Penalty for Low-Rank Representation, NIPS 2011.
LADMPSAP
- 对于三个以上的,同时更新。
Proximal LADMPSAP
concensus problem
这个问题叫做 composite
这个问题叫 separable
Group Sparse Logistic Regression with Overlap
where $S_j$ are the selection matrices.
rewrite $z=\bar S\bar w,\bar S=(S,0),S=(S_1^T,…S_t^T)^T$, and $\bar w=(w^T,b)^T$.
关于 $h(i)$ 的 proximal 算子,另一个是 soft-thresholding operation.
没有要求大家掌握这个证明,只要会结论的参数的证明,
线性化和proximal还是要好好掌握的。
Coordinate Descent
- 一个拍脑袋也能想到的算法
- $x{i}^{k+1}=\arg \min{xi} f(x_1^{k+1},x_2^{k+1},…x{i-1}^{k+1},xi,x{i+1}^k,…x_n^k)$
- 基本原则就是每个subproblem都要好解。
Block Coordinate Descent
- Convergence: 收敛性有个很直观的反例。
example: adaboost
example: Sequential Minimal Optimization
选择两个变量 $\lambda1,\lambda_2$ 违反了KKT条件,让 $\lambda_i,i\not=1,2$ 固定,且 $\lambda_1y_1+\lambda_2y_2=C=-\sum{i\not=1,2}\lambda_iy_i$,用 $\lambda_2=y_2(C-\lambda_1y_1)$ 替代,变成($\alpha,\beta$ 是一些常数)
这东西有一个close form的solution。
Randomized Algorithms
Stochastic Gradient Descent (SGD)
Theorem1
assume SGD is run for $T$ times, with $\eta=\sqrt {\frac{B^2}{\rho^2T}}$. Assume also that for all $t$, $v_t \le \rho$ with probability 1, then
注意是平均意义上的收敛。
这个的证明分成两步,第一个是
如果 $w^{(t+1)}=w^{(t)}-\eta v_t$,
满足
注意这里如果让 $\eta=\frac{B}{\rho\sqrt T}$ 就有
第二个是:
对于每一个有
variant1
如果加一步,每次迭代之后做一个argmin,
因为 $||w-u||^2\ge ||v-u||^2$,如果 $v=\arg\min_{x\in \mathcal H} ||x-w||^2$,所以
前面的结论依然可以继承下来。
variant2:$\eta_t=\frac{B}{\rho \sqrt t}$
variant3: 可能可以只用partial的平均,而不是所有的平均,只用后 $\alpha T$ 论。
关于 $\lambda$ 强凸:
就可以让收敛率提升
推导是,因为
代入之前的公式,就多了一项。
然后这里 $\eta_t$ 的取值就可以几乎完全是通过差分来实现的,就是考虑前后两项在某个地方要消掉。
其它方法:
- 除以梯度平方累计的根号(但不是无量纲化的)
- sgn SGD 要么更新正一要么更新负一
Random Coordinate Descent
选 $\eta=R/L\sqrt{2/nt}$
随机选一个,然后优化。
lzc:我个人感觉优化算法有一个计算量守恒的定理,但是没法定量描述
Stochastic ADAM/ADAN
技巧1
技巧2:两种加速方法,一种是基于momentum的(Adam),一种是Nesterov的
以及
有一个新的formulation
用这个方法加上动量的一阶矩和二阶矩
林教授:投了两次没中,觉得应该学一学Adam,虽然也没发表但是已经十几万引用了
什么是凸集
什么是强凸函数
什么是对偶范数
什么是 $L$-smooth
怎么判断是否是凸函数
怎么求对偶问题
怎么判断是否满足SCQ条件
- 只要看是否存在一个点满足所有非凸的条件。
如何给出KKT条件
- 四个要求,缺一不可。
矩阵的范数是怎么样的
- $||A||_{2,1}$ 表示所有行的 $L_2$ 范数的和。
- Frobenius范数是所有元素平方的和的根号
- 谱范数是最大的奇异值
- 1范数是每一列绝对值之和的最大值
- oo范数是每一行的绝对值之和的最大值。记忆方法可以考虑1是竖着的oo是横着的。
如何给出proximal
- $proxcf(V)=\arg \min_A ||A||{2,1}+\frac{1}{2c}||A-V||_F^2$
- 这个应该是能求出来的闭式解
如何计算收敛率
- 如果是 r-linear,就是误差的比率(牛顿法某些情况下)
- 如果是 Q-linear,就是误差的一个上界的比率。
什么是Frank-Wolfe算法
- 定义域内找最小的方向
什么是LADM
- 每次优化一个变量,以及一个 $\lambda$,用增强拉格朗日乘子
怎么计算伴随算子
- 高等代数的内容