CS 285: Lecture 20, Inverse Reinforcement Learning, Part 1 (youtube.com)
The imitation learning perspective
Standard imitation learning:
- copy the actions performed by the expert
- no reasoning about outcomes of actions
Human imitation learning:
- copy the intent of the expert
- might take very different actions!
Inverse reinforcement learning
Infer reward functions from demonstrations
给定了 $s\in S,a \in A,p(s’\mid s,a)$以及一些从 $\pi^*(\tau)$ 中采样的轨迹
- 求 $r_{\psi}(s,a)$ (reward parameters)
- 然后用它来求 $\pi^*(a\mid s)$
feature matching IRL
如果我们用linear的方法来建模reward function。
如果这些feature $f$ 是重要的:
我们想要 $\pi^{r\psi}$ 作为一个关于 $r\psi$ 的最优的policy,也就是希望
这里的
这里 $\rho(s,a)$ 表示在数据集中 $(s,a)$ 这样的pair出现了多少次。
而左边的部分,如果环境未知可以用sample的方法来作同样的事情(expensive but useful),如果环境不大而且已知可以用动态规划来学。
为了找到最佳的参数,借鉴SVM中的 maximum margin principle。
一个很启发式的方法,找到那个让expert非常厉害的 $\psi$。
Issues:
- Maximizing the margin is a bit arbitrary
- What if the “expert” demonstrations are suboptimal? We could add slack variables as in a SVM setup.
- It might be ok for this linear case but become very messy for ANN reward approximation.
optimal control as a model of human behavior
回到这张图
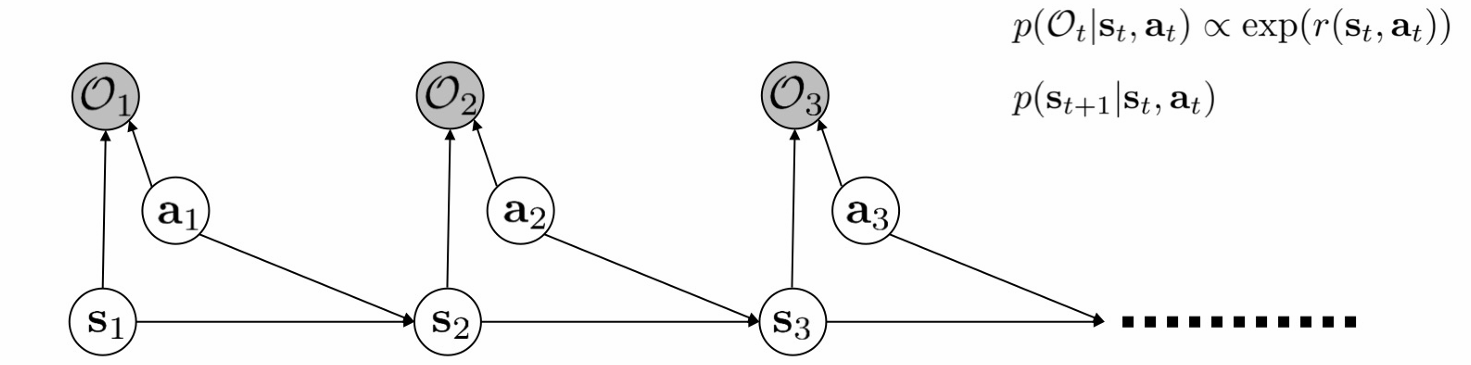
现在我们要inference the reward function.
这里 $\psi$ 是reward的一个参数。
那么最大似然估计的方法,我们从 $\pi^*$ 中sample 一些 $\tau_i$
所以IRL partition function就是
这里的
代入展开我们有
这里第二项就是 $\tau$ 发生的概率,也就写成
展开
利用
得到
那么如果定义
就有
这样我们就得出了 MaxEnt IRL Algorithm

关于为什么叫MaxEnt,据说是,在 $r\psi (s_t, a_t) = \psi^T f(s_t, a_t)$ 的时候他优化了 $max\psi \mathcal{H} \left( \pi^{r\psi} \right)
\space \space s.t.
E{\pi^{r\psi}}[f] = E{\pi^\star} [f]$推导 【逆强化学习-2】最大熵学习(Maximum Entropy Learning)_最大熵逆向强化学习代码-CSDN博客 比较好,从最大熵的目标函数除法,利用拉格朗日乘子法重新得到了那个优化公式。
To apply this in practical problem settings, we need to handle…
- Large and continuous state and action spaces
- States obtained via sampling only
- Unknown dynamics
注意我们的公式其实就是:
第一项是expert的policy,第二项是目前的policy。
一个直观的想法是学习 $p(at \mid s_t, O{1:T}, \psi)$,不过这会比较慢。
一个想法是用一个分布 $\pi\theta(a_t\mid s_t)$ 去近似 $p(a_t \mid s_t, O{1:T}, \psi)$。那么从 $\pi_\theta$ 中取就需要一个重要性采样。
这里 $wj = \frac{p(\tau) exp ( r\psi (\tauj) ) }{\pi\theta(\tauj)}$,展开的话就是 $w_j = \frac{exp \left( \sum_t r\psi (st, a_t)\right)}{\prod_t \pi\theta (a_t \mid s_t)}$。
所以假设我们已经有 $\pi\theta,\pi^*$ 之后,可以用 $\psi \leftarrow \psi + \alpha \nabla \psi L(\psi)$ 来更新 reward function。
在此之外,固定当前的reward function,对policy也可以更新
持续迭代更新reward function和policy。
其中Rewad Function往能使专家行为产生高价值同时使当前Policy行为产生低价值的方向跑,然后Policy往能在当前Reward下产生高价值的行为方向跑,从而又体现出了对抗的思想!

Inverse RL as a GAN
- Finn, Christiano et al. “A Connection Between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models.”
假设读者已经对GAN有所了解,GAN的优化目标是
而
注意到如果
那么这个判别器是最优的。
对于InverseRL我们知道 $\pi\theta(\tau) \propto p(\tau)\exp (r\psi(\tau))$
这里的
这样的话就可以用GAN的思路来看待offline RL。
Can we just use a regular discriminator?